PII Detection in Multiple File Type
Personally Identifiable Information(PII) is any data that could potentially identify a specific person. PII may include name, address, email, telephone number, date of birth, passport number, fingerprint, driver’s license, credit/debit card, social security number etc. With the onset of the GDPR, CCPA and the trend of people being more aware of how their personal information is being used, being able to detect PIIs is becoming more important than ever before.

For this project, we tried to write a python script that is able to detect different PIIs from file types like “.docs”, “.csv”, “.xlsx”, “.txt”, “.pdf”, “.jpeg”, “.png”. This project mostly uses Presidio which is a Microsoft Open Source project. Presidio can also be used to detect PII on images for file types like “.pdf”, “.jpeg”, “.png” where OCR techniques are implemented before analyzing text. We will also go through the different ways we have customized Presidio so that it is able to detect more types of PIIs in our dataset.
Python Libraries Used
To install Presidio, we first had to install presidio-analyzer and presidio-image-redactor using pip. Presidio-analyze is used to read text files and presidio-image-redactor is used to read image files. Presidio analyzer requires spaCy language model so we also had to download it separately. You can find more detailed instructions on how to download Presidio here. We also loaded few libraries that enable Presidio to analyze and anonymize a table or data frame.
Other than Presidio, we also included libraries to convert files eg. converting from docx to text file or converting pdf to images. The full list of packages used in the script are included here:
import pandas as pd
import numpy as np
#for structured/semi-structured data on presidio
from typing import List, Optional, Dict, Union, Iterator, Iterable
from dataclasses import dataclass
import collections
#to use presidio on non-image files
from presidio_analyzer import AnalyzerEngine, RecognizerResult
from presidio_analyzer import PatternRecognizer
from presidio_analyzer import Pattern
#to use presidio on images
from presidio_image_redactor import ImageRedactorEngine
from presidio_image_redactor import ImageAnalyzerEngine
#read images
from PIL import Image
import os
import fnmatch #matching file names
from pandas import read_excel #reading excel files using presidio
import docx2txt #converting docx to text file
from pdf2image import convert_from_path #converting pdf to imagesCustomizing Presidio
Presidio has a number of predefined recognizers for PII entities. It already comes with a trained model that is able to detect credit card, crypto, date time, domain name, email address, IBAN code, IP address, nationality religious or political group (NRP), person’s first or last name, phone number, medical license, bank number, driver license, taxpayer identification number, passport number, social security number etc. Outside of the entities that are already included in Presidio, we can also created new entities and classes to improve Presidio further. Presidio normally reads and analyzes unstructured data but you can also set it to read structured data.
Structured/Semi-Structured Data: For Presidio to read structured data, BatchAnalyzerEngine class was created to analyze the data. The class can analyze both lists and dictionaries. One can also include the BatchAnonymizerEngine class to anonymize the PII data. The data shared in class was in a structured format, so we felt that it was necessary for us to treat it as structured data. More on how to use structured/semi-structured data can be found here.
@dataclass
class DictAnalyzerResult:
"""Hold the analyzer results per value or list of values."""
key: str
value: Union[str, List[str]]
recognizer_results: Union[List[RecognizerResult], List[List[RecognizerResult]]]
class BatchAnalyzerEngine(AnalyzerEngine):
"""
Class inheriting from AnalyzerEngine and adds the funtionality to analyze lists or dictionaries.
"""
def analyze_list(self, list_of_texts: Iterable[str], **kwargs) -> List[List[RecognizerResult]]:
"""
Analyze an iterable of strings
:param list_of_texts: An iterable containing strings to be analyzed.
:param kwargs: Additional parameters for the `AnalyzerEngine.analyze` method.
"""
list_results = []
for text in list_of_texts:
results = self.analyze(text=text, **kwargs) if isinstance(text, str) else []
list_results.append(results)
return list_results
def analyze_dict(
self, input_dict: Dict[str, Union[object, Iterable[object]]], **kwargs) -> Iterator[DictAnalyzerResult]:
"""
Analyze a dictionary of keys (strings) and values (either object or Iterable[object]).
Non-string values are returned as is.
:param input_dict: The input dictionary for analysis
:param kwargs: Additional keyword arguments for the `AnalyzerEngine.analyze` method
"""
for key, value in input_dict.items():
if not value:
results = []
else:
if isinstance(value, str):
results: List[RecognizerResult] = self.analyze(text=value, **kwargs)
elif isinstance(value, collections.abc.Iterable):
results: List[List[RecognizerResult]] = self.analyze_list(
list_of_texts=value,
**kwargs)
else:
results = []
yield DictAnalyzerResult(key=key, value=value, recognizer_results=results)Regular Expressions: Presidio’s detection capabilities can be extended using EntityRecognizer objects. There are different types of recognizer classes in Presidio. PatternRecognizer is a class for supporting regex and context support. For our project, we created new entities for zip code and passwords using regular expressions. The entities also take into consideration surrounding words related to zip code and password.
# Adding zip code to the entity list. Make sure zip code is turned into a string for regex to work
zip_pattern = Pattern(name="zip_pattern",regex= '(\\b\\d{5}(?:\\-\\d{4})?\\b)', score = 0.5)#regular expression that selects zip codes
zip_recognizer = PatternRecognizer(supported_entity="ZIPCODE", #name of new entity
patterns = [zip_pattern],
context= ["zip","zipcode"]) #consider any surrounding words that has zip or zipcode in it
batch_analyzer.registry.add_recognizer(zip_recognizer) #adding new zip code recognizer to batch_analyzer
analyzer.registry.add_recognizer(zip_recognizer) #adding new zip code recognizer to analyzer#Adding Password
password_pattern = Pattern(name="password_pattern",regex= '^(?=.*?[A-Z])(?=.*?[a-z])(?=.*?[0-9])(?=.*?[#?!@$%^&*-]).{8,}$', score = 0.5)#regular expression that selects password
password_recognizer = PatternRecognizer(supported_entity="PASSWORD", #name of new entity
patterns = [password_pattern],
context= ["password"]) #consider any surrounding words that has password in it
batch_analyzer.registry.add_recognizer(password_recognizer) #adding password recognizer to batch_analyzer
analyzer.registry.add_recognizer(password_recognizer) #adding password recognizer to analyzer
Deny-Lists: PatternRecognizer also supports deny-list based recognizers. For our purposes, we uploaded state and city lists so that Presidio can easily detect what they are. Similar to regular expressions, we can also include context within the entities. As state and city names don’t tend to change we decided to take this list-based approach. Data for states and cities were collected from here.
#Adding State to the entity list
state_recognizer = PatternRecognizer(supported_entity="STATE", #name of new entity
deny_list=list(location_list['State short'].dropna().unique()), #only include unique states, drop null values
context= ["state","address"]) #consider any surrounding words that has state or address in it
batch_analyzer.registry.add_recognizer(state_recognizer) #adding new state recognizer to batch_analyzer
analyzer.registry.add_recognizer(state_recognizer) #adding new state recognizer to analyzer#Adding List of Cities
city_recognizer = PatternRecognizer(supported_entity="CITY", #name of new entity
deny_list=list(location_list['City'].dropna().unique()), #only include unique city, drop null values
context= ["city","address"]) #consider any surrounding words that has city or address in it
batch_analyzer.registry.add_recognizer(city_recognizer) #adding new city recognizer to batch_analyzer
analyzer.registry.add_recognizer(city_recognizer) #adding new city recognizer to analyzer
Working with Different File Types
While working with different file types, we can group them together into two major groups: text files and image files. The processing for analyzing text and image file was different. Once they were analyzed, the result was put into different data frames based on their file type. The dataframe from different file types were all put together in a separate csv file that included all the results and the relevant files they were detected from.
Text Files
“.txt”, “.csv”, “.xlsx”, “.docx” were considered as text file. “.txt”, “.csv”, “.xlsx” were first read in as dataframes. “.docx” was converted into a “.txt” file and then read in as a dataframe. The data frame was converted into a dictionary for the batch analyzer class to analyze the data. All data type was also converted into strings for Presidio to read through them properly. The final result after analyzing the data had three columns: key, value, and recognizer result. Key was the column names, value was the data available in the dataframe and recognizer result was the result received from Presidio. We decided to drop the value column and include a file name column in the final dataframe for each file type.
#detect txt files and analyze for piis
for filename in os.listdir('.'):
if fnmatch.fnmatch(filename, 's_pii_*.txt'): #search for files starting with s_pii and ending with .txt
df = pd.read_csv(filename, index_col = 0).reset_index(drop = True) #reading the file
df = df.astype(str) # convert everything into string
df_dict = df.to_dict(orient="list") #df being converted to a dictionary
analyzer_results = batch_analyzer.analyze_dict(df_dict, language="en") #analyzing the data
analyzer_df = pd.DataFrame(analyzer_results) #converting into a dataframe
presidio_df = pd.DataFrame(list(analyzer_df['recognizer_results']), analyzer_df['key']).reset_index() #selecting only the results
presidio_df.insert(0, 'filename', filename, True) #include the name of the original file next to everything
#detect csv files and analyze for piis
for filename in os.listdir('.'):
if fnmatch.fnmatch(filename, 's_pii_*.csv'): #search for files starting with s_pii and ending with .csv
csv = pd.read_csv(filename) #reading the file
csv = csv.astype(str).replace('nan',np.nan) #replace all null values with 'nan'
df_dict_csv = csv.to_dict(orient="list") #df being converted to a dictionary
analyzer_results_csv = batch_analyzer.analyze_dict(df_dict_csv, language="en") #analyzing the data
analyzer_df_csv = pd.DataFrame(analyzer_results_csv) #converting into a dataframe
presidio_df_csv = pd.DataFrame(list(analyzer_df_csv['recognizer_results']), analyzer_df_csv['key']).reset_index() #selecting only the results
presidio_df_csv.insert(0, 'filename', filename, True) #include the name of the original file next to everything
#detect xlsx files and analyze for piis
for filename in os.listdir('.'):
if fnmatch.fnmatch(filename, 's_pii_*.xlsx'): #search for files starting with s_pii and ending with .xlsx
xlsx = pd.read_excel(filename, engine = 'openpyxl') #reading the file
xlsx = xlsx.astype(str).replace('nan',np.nan) #replace all null values with 'nan'
df_dict_xlsx = xlsx.to_dict(orient="list") #df being converted to a dictionary
analyzer_results_xlsx = batch_analyzer.analyze_dict(df_dict_xlsx, language="en") #analyzing the data
analyzer_df_xlsx = pd.DataFrame(analyzer_results_xlsx) #converting into a dataframe
presidio_df_xlsx = pd.DataFrame(list(analyzer_df_xlsx['recognizer_results']), analyzer_df_xlsx['key']).reset_index() #selecting only the results
presidio_df_xlsx.insert(0, 'filename', filename, True) #include the name of the original file next to everything
#detect docx files and convert into txt files
for filename in os.listdir('.'):
if fnmatch.fnmatch(filename, 's_pii_*.docx'): #search for files starting with s_pii and ending with .docx
MY_TEXT = docx2txt.process(filename) # converting docx file into txt files
with open("pii_docx_made.txt", "w") as text_file: #saving file as txt file
print(MY_TEXT, file=text_file)
docx = pd.read_csv("pii_docx_made.txt", sep = "\t") #reading the txt file
df_dict_docx = docx.to_dict(orient="list") #df being converted to a dictionary
analyzer_results_docx = batch_analyzer.analyze_dict(df_dict_docx, language="en") #analyzing the data
analyzer_df_docx = pd.DataFrame(analyzer_results_docx) #converting into a dataframe
presidio_df_docx = pd.DataFrame(list(analyzer_df_docx['recognizer_results']), analyzer_df_docx['key']).reset_index() #selecting only the results
presidio_df_docx.insert(0, 'filename', filename, True) #include the name of the original file next to everythingImage Files
“.pdf”, “.jpg”, “.png” files would fall into this bucket of image files. “.pdf” files were converted into “.jpg” files before passing it through the image analyzer. Image analyzer analyzes the image and then gives a list of PIIs that it thinks is included in the file. The analyzed data is then included in a dataframe. The code also saves a redacted image into the folder that covers the PII data. The same process was implemented for “.jpg” and “.png” file. Presidio Image Redactor was able to read both .jpg and .png files.
#detect pdf files and convert into jpg files
for filename in os.listdir('.'):
if fnmatch.fnmatch(filename, 's_pii_*.pdf'):
# Store Pdf with convert_from_path function
images = convert_from_path(filename)
for i in range(len(images)): # Save pages as images in the pdf
images[i].save(str('made_')+ filename + str(i) +'.jpg', 'JPEG') #convert into jpg files
#reading the jpg file created from pdf
for filename in os.listdir('.'):
if fnmatch.fnmatch(filename, 'made_s_pii_pdf*.jpg'):
img_pdf = Image.open(filename)
img_pdf = img_pdf.convert('RGBA')
result_pdf = image_analyzer.analyze(image=img_pdf)#analyzing image
#image_analyzer = ImagePiiVerifyEngine() #to see the result of the analysis
#result_pdf = image_analyzer.verify(image=img_pdf) #to see the result of the analysis
presidio_df_pdf = pd.DataFrame(result_pdf)
presidio_df_pdf.insert(0, 'filename', filename, True)#inserting filename
redacted_image_pdf = redactor.redact(image=img_pdf)#saving redeacted image on the folder
redacted_image_pdf.save(str('redacted') + filename + ".png") # save the redacted image onto the computer
#detect jpg files, analyze for pii and created a redacted file
for filename in os.listdir('.'):
if fnmatch.fnmatch(filename, 's_pii_*.jpg'):
img_jpg = Image.open(filename)
result_jpg = image_analyzer.analyze(image=img_jpg)#analyzing image
#image_analyzer = ImagePiiVerifyEngine() #to see the result of the analysis
#result_pdf = image_analyzer.verify(image=img_pdf) #to see the result of the analysis
presidio_df_jpg = pd.DataFrame(result_jpg)
presidio_df_jpg.insert(0, 'filename', filename, True)#inserting filename
redacted_image_jpg = redactor.redact(image=img_jpg)#saving redeacted image on the folder
redacted_image_jpg.save(str('redacted') + filename + ".png") # save the redacted image
#detect png files, analyze for pii and created a redacted file
for filename in os.listdir('.'):
if fnmatch.fnmatch(filename, 's_pii_*.png'):
img_png = Image.open(filename)
result_png = image_analyzer.analyze(image=img_png)#analyzing image
#image_analyzer = ImagePiiVerifyEngine() #to see the result of the analysis
#result_pdf = image_analyzer.verify(image=img_pdf) #to see the result of the analysis
presidio_df_png = pd.DataFrame(result_png)
presidio_df_png.insert(0, 'filename', filename, True)#inserting filename
redacted_image_png = redactor.redact(image=img_png)#saving redeacted image on the folder
redacted_image_jpg.save(str('redacted') + filename + ".png") # save the redacted imageResults
In the end all of the dataframe from different file types were joined together to create one final output called “result_structured.csv”
frames = [presidio_df, presidio_df_csv, presidio_df_xlsx, presidio_df_docx,
presidio_df_pdf, presidio_df_jpg, presidio_df_png]
final = pd.concat(frames) #joining all dataframes created from different types of files.
final.to_csv("result_structured.csv") # saving the dataframe as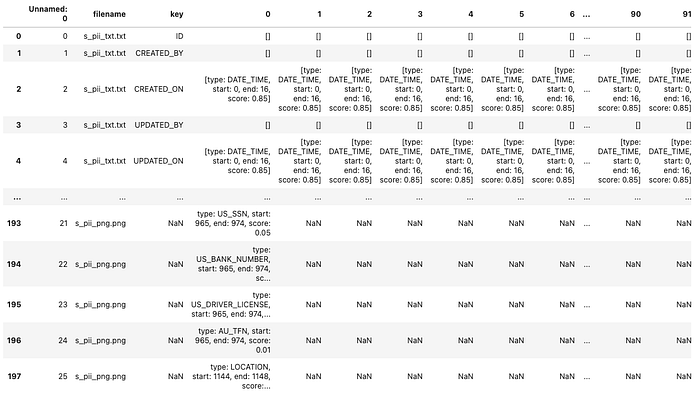
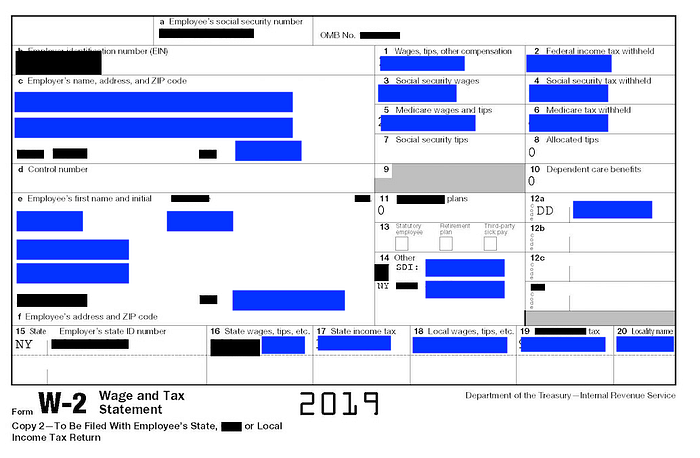
The following is a sample of the redacted W2 after using Presidio. Black boxes are the data detected by Presidio and blue boxes were covered by me to cover personal information. I tested the code on an actual W2 and it was successfully able to detect Social Security number, Employer Identification Number and Employer’s state ID number.
Other Work
Outside of the steps described above, we also tested with a customized NLP model using spaCy. The model was trained on username data as the existing Presidio model was quite bad at detecting username as a PII. However, we decided not to use the model as it was not giving us good results. The Presidio model was quite good at detecting people’s first and last name but it did not give a 100% accuracy rate. Other than using Presidio, we also spend significant time trying to run PIIDetect, PIICatcher and PIIanalyzer. As these libraries are quite old, not updated regularly, and did not have a lot of documentation online, we had to spend a lot of time trying to make them work.
Conclusion and Future Scope
In the future, we plan on using other libraries like PIIDetect, PIICatcher, and PIIanalyzer to see how the results compare against Presidio. We would also like to use Ensemble techniques that take into consideration learnings from all of the models to predict for PIIs. Further exploration is also needed to explore other types of Named Entity Recognizer models that is trained on more names, usernames, and addresses. In the current script, some of the file types are only considering structured file types, in the future we would like to expand it to include unstructured file types.
Code for this project is available on Github







